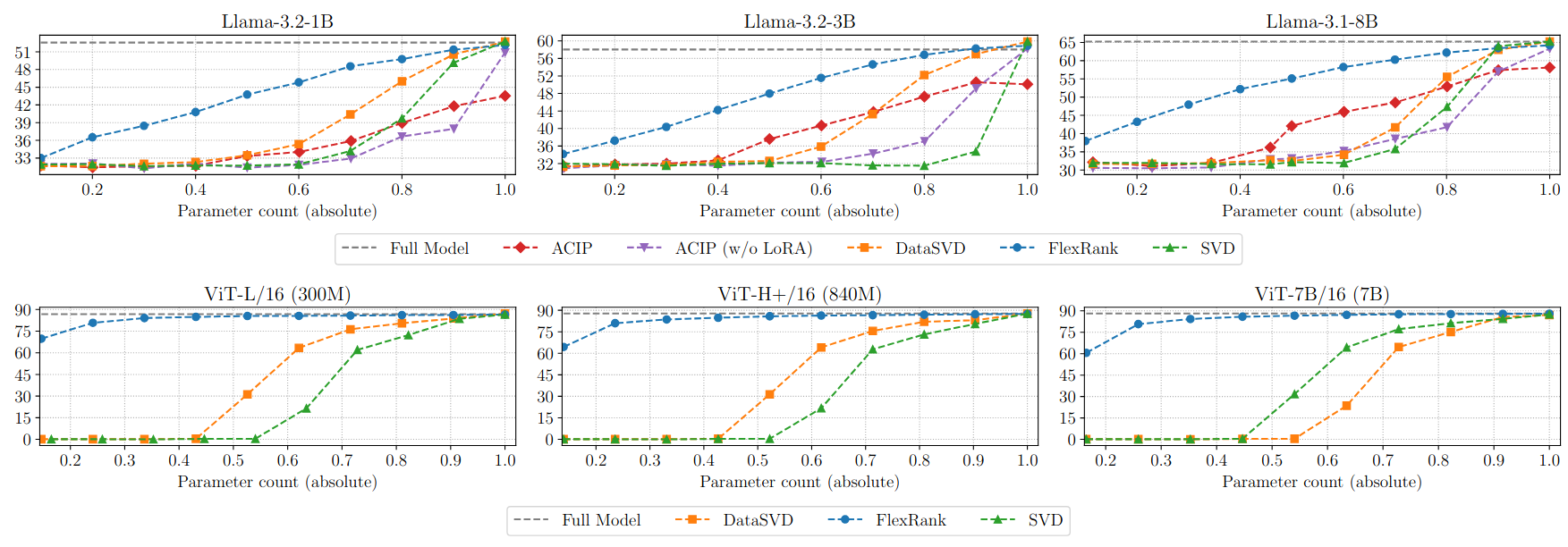
The ablations show that FlexRank is more than SVD plus training: both the rank allocation and the nested training procedure
are doing important work.
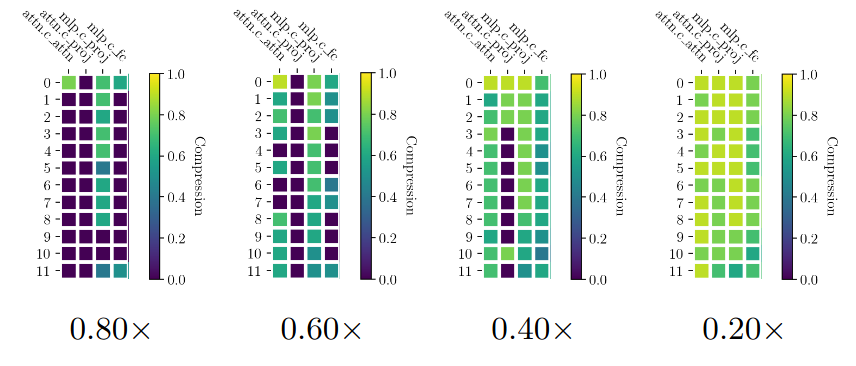
🔍 Rank profiles are non-uniform. In the heatmaps below, each column corresponds to a GPT-2 module and each row to a target model size.
If uniform compression were enough, the heatmaps would look almost flat. Instead, FlexRank preserves more capacity in specific modules,
showing that the dynamic-programming search identifies where rank is most valuable.
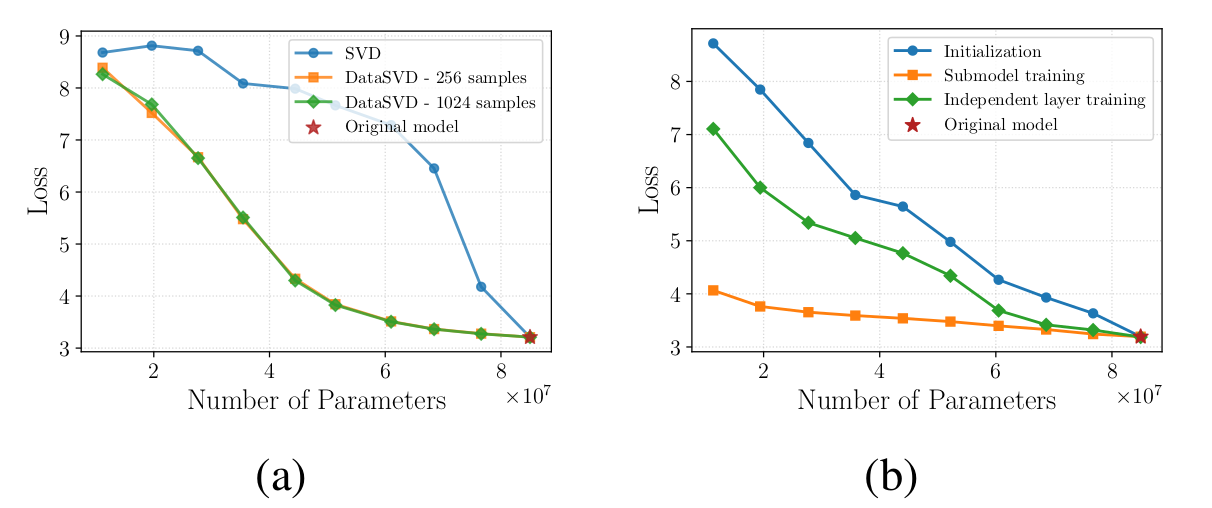
📈 Initialization alone does not solve elasticity. In Figure 7(a), the DataSVD curves with 256 and 1024 calibration samples almost overlap,
showing that a small calibration set is already enough to estimate the layer-wise decomposition. However, the loss remains far from the
original model at smaller parameter counts, so better initialization alone is not enough.
🧠 Joint nested training is the key consolidation step. Figure 7(b) shows that independently adapting each layer is still much weaker
than training the selected submodels end-to-end: the model needs to repair cross-layer interactions, not only local reconstruction errors.
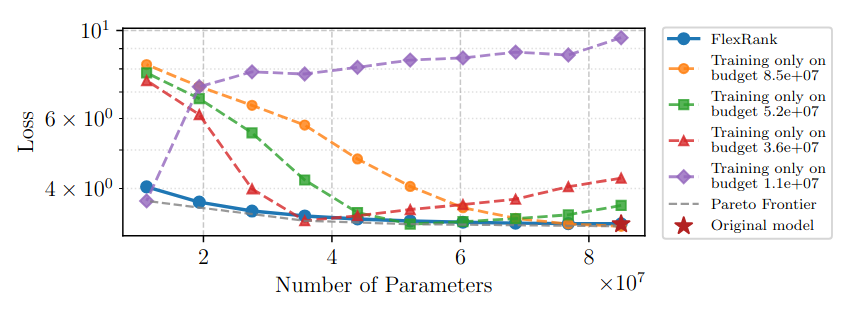
Figure 8 then isolates the role of budget sampling: each single-budget model is strong near the budget it was trained for, but fails to
trace the full Pareto curve. FlexRank stays close to the best curve because it distills many nested budgets into the same shared weights.